

1. 서 론
2. 연구 방법 및 데이터
2.1 연구방법
2.2 데이터
2.3 밀집도
2.4 지반함몰 위험도 예측 모델
2.5 SHAP 기반 설명가능성 분석
3. 연구 결과
3.1 변수 중요도 분석
3.2 지반함몰 예측 위험도에 따른 변수분포
3.3 밀집도에 따른 지반함몰 위험도 관계 분석
4. 결 론
1. 서 론
국내 도심지 중심에서 발생하는 지반함몰은 상·하수관로와 같은 지하매설물의 손상, 다짐 불량, 굴착공사 등이 주요 원인으로 알려져 있다. 그 중에서도 지하매설물의 손상에 의한 토립자의 유실이 지반함몰 사고의 가장 큰 원인으로 지목되고 있다(Lee et al., 2022b). 지하매설물은 인구밀도가 높은 도심지에 집중적으로 매설되어 있기 때문에 지반함몰 사고 발생 시 인명 및 재산 피해를 야기할 수 있고 커다란 사회적 혼란을 야기할 수 있다(Lee et al., 2022b). 따라서 지반함몰의 발생 원인 및 메커니즘 분석을 통한 위험인자를 선정하여 지반함몰 사고 위험을 관리할 필요가 있다.
서울시에서 2010년부터 2014년 7월까지 발생한 지반함몰 사례를 분석한 결과, 대부분은 노후화된 상·하수도관의 손상과 같은 지하시설물 결함에서 비롯된 것으로 보고하였다(Seoul, 2014). 지반함몰은 다짐 등과 같은 외부 충격이나 열화로 인해 관이 파손되면, 균열 부위를 통해 지하수 흐름이 집중되고 그 과정에서 토립자가 지속적으로 유실되면서 관 주변부에 공동이 형성되고 점차 확대되는 메커니즘을 가진다(Jin, 2018). 즉, 시간이 지남에 따라 관로의 노후가 진행되고 각종 굴착공사가 반복되면 토사 유실의 위험은 더욱 커져 지반함몰 발생 가능성이 증가할 수 있다.
따라서 토사의 유실을 간접적으로 확인할 수 있는 인자를 활용하여 지반함몰 사고 관리를 위한 연구가 다양하게 수행되고 있다. 일본에서는 지반함몰 사고에 대한 다양한 연구가 선행되었다. 지반 내 공동 발생의 메커니즘 규명을 위해 일본 표준사를 활용하여 공동을 모사한 실내 모형 실험에 관한 연구를 수행하였고(Kuwano et al., 2006), 모형 토조를 제작하여 하수관 균열을 모사하고 X-ray와 CT 등의 장비를 통한 공동 발생의 시각화에 대한 연구가 발표되었다(Mukunoki et al., 2009).
또 다른 연구로는 유한요소법을 활용하여 지반 공동 및 이완영역을 모사하고(You et al., 2017), 수치해석을 통해 지하매설물 손상 위치와 지반의 상대밀도, 지층조건에 따른 지반함몰 발생 메커니즘에 대해 발표되었다(Lee et al., 2022a). 최근에는 AI 기술을 통한 지반함몰 위험관리에 관한 연구가 수행되고 있다. 지반함몰 영향인자 도출 및 영향인자의 가중치 산정을 위해 기계학습 알고리즘인 Decision Tree와 의사결정 지원을 위한 계량적인 의사결정 방법인 AHP 분석을 수행한 연구가 발표된 바 있다(D. Takeuchi et al., 2017). 또한, 지하매설물의 속성정보와 밀집도를 활용하여 국내 지반함몰 위험도 예측 모델을 개발한 연구가 발표되었다(Lee et al., 2022c). 추가적으로 지층두께, 투수계수와 같은 지반환경 인자를 추가하여 지반함몰 위험도 예측 모델을 고도화하는 연구도 발표되었다(Lee et al., 2022b). 이와 같이, 다양한 접근방법을 통해 지반함몰 발생 원인 및 메커니즘을 분석하고 영향인자를 선정하기 위한 연구가 수행되었다. 하지만 지반함몰은 다양한 원인이 복합적인 작용에 의해 발생하는 현상이기 때문에, 단일 인자를 통해 정량화된 사고 위험도 관리는 어려운 실정이다. 따라서 본 연구에서는 기존 연구에서 개발된 지하매설물 및 밀집도 기반 지반함몰 위험도 예측 모델에 SHAP 기반 설명가능한 AI(XAI) 를 적용하였다. 이를 통해 지반함몰 위험도를 3단계 등급으로 분류하고, 각 위험등급에서 영향력을 미치는 핵심 설명변수의 중요도와 기여 방향성을 해석하였다. 특히, 밀집도가 지반함몰 위험도에 미치는 영향을 정량적으로 분석하고, 밀집도가 고위험 등급으로 전환되는 임계값을 도출하여 제시하였다. 본 연구를 통해 지반함몰 사고 대응을 위해 우선중점관리 구간을 선정할 수 있는 정량적인 지표를 제시할 수 있다.
2. 연구 방법 및 데이터
2.1 연구방법
본 연구는 대한민국의 도심지를 중심으로 개발된 XGB 기반 지반함몰 위험도 예측 모델과 XAI를 결합하여 지반함몰 사고 위험도를 예측하고 위험도에 영향을 미치는 핵심 변수의 중요도를 확인하였으며, 밀집도가 사고에 영향을 미치는 정도를 정량화하였다. 이를 위해서 기존 연구(Lee et al., 2024)를 통해 개발된 XGB 기반 지반함몰 위험도 예측 모델을 활용하여 대상지역의 지반함몰 위험도를 3단계로 예측하였다(Li, 2022). 해당 모델에 SHAP 기반의 XAI를 추가하여 위험도를 결정하는데 활용된 인자의 중요도를 확인하였으며, SHAP dependence 분석을 통해 변수 값 변화에 따른 위험 기여도의 방향성을 분석하였다. 또한, 대표적인 지반함몰 영향인자로 보고된 밀집도에 대해서 SHAP 변화 패턴을 분석하고, 위험도에 영향을 미치는 임계값을 정량화하여 도출하였으며, 전체 데이터를 모델로 재예측하여 위험등급에 따른 실제 밀집도 값의 분포를 비교함으로써 임계값의 타당성을 검증하였다.
2.2 데이터
본 연구에서는 선행 연구(Lee et al., 2023)에서 구축된 지반함몰 위험도 예측용 데이터셋을 활용하였다. 대상지역은 대한민국 내 대표적인 도심 지역으로 설정하였으며, 위험도 분석을 위한 단위는 500m × 500m 크기의 Grid로 구분하였다. 대상지역에 총 2,391개의 Grid가 생성되었으며, 각 Grid는 지반함몰 예측을 위한 기본 분석 단위로 사용되었다.
각 Grid에는 6종 지하매설물(상수도, 하수도, 전력, 가스, 지역난방, 통신)의 공간정보 및 속성정보(관경, 길이, 매설년도)와 함께 지반함몰 발생 이력 데이터가 포함되어 있다. 6종 시설물은 하나의 지하매설물로 병합하여 분석하였으며, 매설관의 활용년수, 관경, 관로 길이를 주요 속성 데이터를 변수로 구성하였다. 원본 데이터에는 결측치 및 오류값이 다수 존재하였으므로, 실제 분석에 활용 가능한 변수만 선별하여 사용하였다. 또한, Grid 내 매설관의 총 길이를 기준으로 선형밀도 분석을 통해 지하매설관의 밀집도를 산출하여 지반함몰 발생에 영향을 미치는 잠재적 인자로 활용하였다.
모델 성능 향상을 위해 속성정보의 값을 일정 구간으로 분류하는 전처리 과정을 수행하였다. 관로의 활용년수를 5년 단위, 관경은 50mm 단위로 구분하였으며, 각 구간에 속하는 관로의 길이를 합산하여 변수 값으로 반영하였다. 예를 들어, Grid 내 매설관의 활용기간이 6년인 경우, ‘Y10’(6~10년 사이의 관로) 구간에 해당하는 관로 길이 변수에 합산하는 방식으로 처리하였다.
출력 데이터는 지반함몰 발생이력을 통한 위험도로 구분하였다. 지반함몰 발생이력은 2008년~2016년까지 발생한 실제 지반함몰 이력데이터를 활용하였다. 이를 기반으로 Grid 내 발생한 지반함몰 건수를 집계하여 위험등급을 산정하였다. 위험등급이 지나치게 세분화되면 지반함몰이 발생하지 않은 Grid가 과도하게 많아져 데이터 불균형이 심화되고 모델의 예측 성능이 저하되는 문제가 발생한다. 이를 방지하기 위해 지반함몰 위험도는 저위험(0), 중위험(1), 고위험(2)의 3개 등급으로 구분하였다. 저위험구간은 지반함몰 발생횟수가 0개인 경우이며, 중위험은 1~2개, 고위험은 3개 이상을 의미한다. Table 1은 활용한 데이터를 나타낸 것이며, Table 2는 활용한 데이터의 기술통계를 나타낸 것이다.
Table 1.
Utilization of data
| Data | Range | |
| Input | Density | Density |
| Y | 5, 10, 15, 20, 25, 30, 35, 40, 45, 50 | |
| DTR | 50, 100, 150, 200, 250, 300, 350, 400, 450, 500 | |
| Output | Risk | 3 Grade (1 Class, 2 Class, 3 Class) |
Table 2.
Descriptive statistics of the data
2.3 밀집도
밀집도는 Grid 내에 지하매설물이 어느정도 매설되어 있는지 확인할 수 있는 지표이다. 기존 연구에 따르면 관로의 밀집도는 지반함몰과 매우 유의미한 상관성을 보이는 것으로 나타났다(Kim et al., 2017). 관로의 밀집도가 높은 지역은 지하매설 관의 매립을 위해 다수의 지반굴착이 발생했을 것으로 유추할 수 있으며, 이에 따라 지반의 교란도가 높은 지역으로 판단할 수 있다. 따라서 기존 연구에서도 관로의 밀집도를 주요 영향인자로 선정하여 모델 개발을 위한 데이터셋에 반영하였다. 밀집도는 ArcGIS의 선형 밀도 분석을 통해 단위 면적에 해당하는 관로의 길이를 계산하는 방법으로 추출하였다.
2.4 지반함몰 위험도 예측 모델
기존 연구에서 개발된 XGB 기반 지반함몰 위험도 예측 모델은 Python 3.8을 활용하였으며, Scikit-learn 라이브러리를 활용하였다. 평가지표는 Accuracy, F1-Score, AUC로 선정하였다. 모델은 활용년수를 5년 단위, 관경은 50mm, 위험도 중위험 등급의 Grid내 지반함몰 발생 개수는 1~3개로 설정하였다. 모델의 결과는 F1-Score 0.620, AUC은 0.860, Accuracy 0.710으로 나타났다.
또한, 각 분류기의 Hyperparameter의 튜닝은 시행착오 방법을 활용하여 최적의 결과를 도출하는 Hyper parameter로 설정하였으며, 선정 XGB모델의 주요 Hyper parameter로는 Table 3에 나타냈다.
Table 3.
Summary of Hyper parameters in the model
| Model | Hyper parameter |
| XGB | Estimators(400), Max_Depth(4), Learning_Rate(0.01) |
2.5 SHAP 기반 설명가능성 분석
기계학습 모델은 비선형적 특징을 갖고 있는 인자를 분석할 때, 우수한 예측 성능이 도출된다(Moon et al., 2016). 하지만, 결과에 대한 해석이 명확하지 못한 단점을 갖고 있다(Moon et al., 2016). 지반함몰과 같은 공공 안전 분야에서는 모델의 예측 결과뿐만 아니라 예측의 근거를 제시하여 사고관리가 이루어져야 한다. 또한, 예측 결과에 대한 신뢰성 확보와 의사결정의 책임성을 확보하는 데 중요한 요소이다. 이러한 문제를 해결하기 위해 본 연구에서는 SHAP을 모델에 적용하였다.
SHAP은 게임이론의 Shapley Value 개념을 기반으로 하며, 각 입력변수가 예측 값에 기여한 정도를 정량화하여 제시하는 설명가능 인공지능 기법이다(Mosca et al., 2022). Shapley Value는 여러 인자가 하나의 결과를 도출할 경우, 각 인자에 대한 결과 기여도를 계산하는 방법이다. 이를 머신러닝에 적용하여 입력변수가 모델 예측에 기여한 상대적 영향력을 평가할 수 있다(Van et al., 2022). Shapley Value의 산출식은 Eq. (1)과 같다(Shapley, 1953).
: Shapley Value
: 전체 변수의 집합
: 변수 를 제외한 가능한 부분집합
: 변수 집합 만을 사용했을 때의 모델의 예측 값
: 에 변수 를 추가했을 때 모델의 예측 값
Eq. (1)를 통해 SHAP은 모든 가능한 변수 조합을 고려하여 개별 변수가 예측 결과에 미치는 기여도를 산출한다. 이를 통해, 각각의 인자가 지반함몰에 영향을 미치는 중요도를 정량적으로 산출하였으며, 인자의 변수 기여도의 방향을 분석할 수 있다. 특히, SHAP은 XGB 모델과의 호환성이 우수한 것으로 알려져 있다(Li, 2022).
3. 연구 결과
3.1 변수 중요도 분석
XGB 모델에서는 모델이 문제를 예측하는 과정에서 활용한 변수의 중요도를 확인할 수 있다. 기존 연구에서 XGB 모델에서 활용한 변수의 중요도는 밀집도, Y20, Y45 순으로 나타났다. Y20은 관로의 활용년수가 16~20년 사이의 관을 의미하고 Y45는 41~45년 사이의 관을 의미한다. 이처럼 밀집도와 노후도가 중요하게 활용된 것으로 알 수 있다(Kim et al., 2017).
Fig. 1은 SHAP summary plot을 통해 각 변수가 지반함몰 위험도 예측에 미치는 기여한 정도를 나타낸 것이다. x축의 SHAP Value는 해당 변수가 모델의 예측값을 어느 방향으로 얼마나 이동시켰는지를 나타내며, 양수(+) 값은 해당 변수가 높은 위험도 예측에 기여한 것이고, 음수(-) 값은 낮은 위험도 예측에 기여한 것을 의미한다(Shapley, 1953). 예를 들어 샘플의 밀집도가 낮아도 다른 변수(노후도 또는 관경)로 인해 위험도가 높게 분류되면, 낮은 밀집도도 양수의 SHAP에 포함될 수 있다. 따라서 summary plot의 분포를 통해 변수의 영향력과 샘플별 기여 방향을 시각적으로 확인할 수 있다(Liu et al., 2022). SHAP summary plot은 각 변수의 영향력이 위험의 증가 또는 감소 방향으로 작용하는 것을 색상과 위치로 직관적으로 보여주는 시각화이다. 그림을 해석한 결과, 밀집도와 관로의 활용년수가 지반함몰 사고 위험도를 예측하는 데 큰 기여도를 나타냈다. 반면에 관경(DTR)은 상대적으로 위험을 판단하는데 낮은 기여도를 나타냈다.

3.2 지반함몰 예측 위험도에 따른 변수분포
기존 연구에서 개발된 XGB기반 지반함몰 위험도 예측 모델을 활용하여, 위험도에 따른 변수의 분포를 나타냈다. 모델에서 지반함몰 위험도는 저위험, 중위험, 고위험으로 3단계로 구분되었다. SHAP summary plot을 통해 지반함몰 위험도 예측에 영향을 미치는 밀집도와 Y5, Y20, Y35을 대상으로 예측 위험도에서의 분포를 확인하였다. Y5와 Y20은 활용년수가 짧은 구간, Y35는 활용년수가 높은 구간으로 해석가능하다. Table 4는 각 인자의 위험도에 따른 평균을 나타낸 것이다. 밀집도는 지반함몰 예측 위험도와 비례관계를 나타내고 있으며, Y5는 반비례 관계를 나타낸다. Y20과 Y35는 명확한 경향은 나타나지 않지만, 고위험 구간에서 관로의 수가 감소하는 경향이 나타났다.
Table 4.
Average value according to risk
| Risk | Density | Y5 | Y20 | Y35 |
| Low | 0.061 | 1,543.778 | 2,308.480 | 4,398.920 |
| Middle | 0.126 | 1,308.676 | 3,305.860 | 5,070.230 |
| High | 0.142 | 949.168 | 586.590 | 1,856.530 |
3.3 밀집도에 따른 지반함몰 위험도 관계 분석
Fig. 2는 지반함몰 위험도 예측 모델이 분석 시 활용한 대표적인 주요인자인 밀집도를 대상으로 SHAP 값과의 관계를 Dependence Plot으로 나타낸 것이다. SHAP Dependence Plot은 특정 변수와 SHAP 값 간의 관계를 시각화한 것으로, 모델 예측값에 영향을 주는 변수의 중요도와 상호작용을 해석할 수 있다. 그래프를 확인한 결과, 밀집도 0.00~0.05, 0.05~0.10, 0.10 이상으로 3가지 구간이 나타난다.
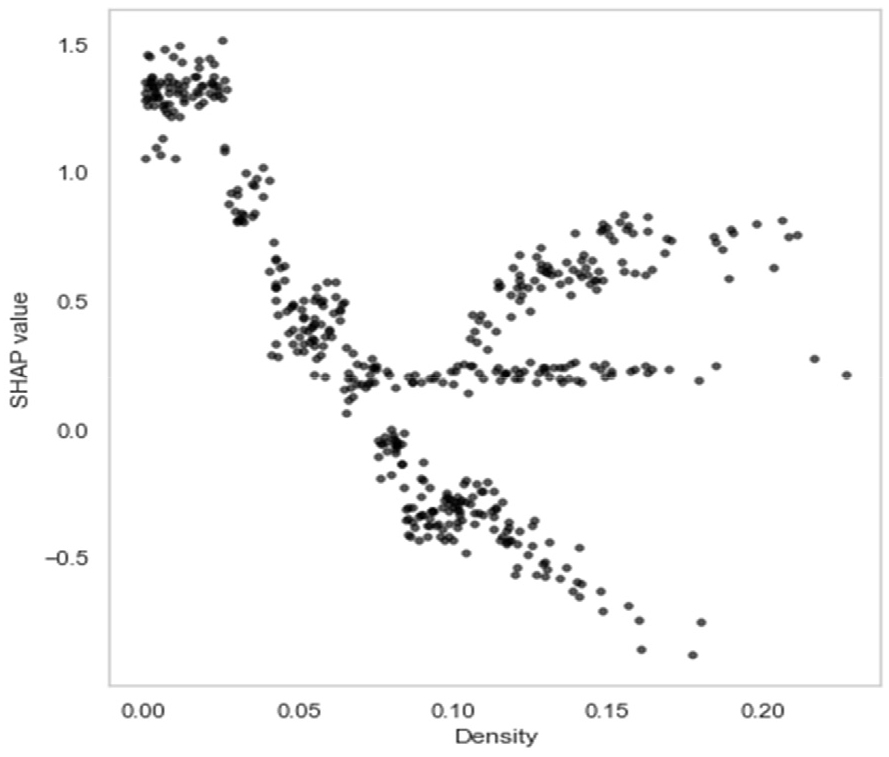
0.00~0.05 구간은 저밀집도 구간으로 높은 SHAP 값에 분포되어 있다. 이는 낮은 밀집도가 위험도를 예측한 클래스를 결정하는데 주요한 기여를 한 것으로 해석할 수 있다. 해당 구간에서 밀집도가 낮다는 것은 관로의 영향이 상대적으로 적다는 것을 의미한다. 따라서 노후관이나 관경의 영향도 같이 감소하여, 상대적으로 밀집도의 기여도가 높아진 것으로 판단된다.
0.05~0.10 구간에서는 SHAP 값이 0.0 부근에 집중되어 있다. 이는 해당 구간에 위치한 밀집도는 지반함몰 위험도 예측에 기여도가 적다는 것을 의미한다. 따라서 밀집도가 0.05~0.10인 구간에서 지반함몰 위험도를 관리하기 위해서는 굴착공사와 지하수위 변화 등 지반함몰에 영향을 미치는 추가 인자분석을 통해 효율적으로 관리할 필요가 있을 것이다.
관로의 밀집도가 0.10 이상인 구간에서는 지반함몰 위험도에 기여도 방향이 양수(+)로 전환되는 것을 확인할 수 있다. 음수(-)인 구간도 존재하지만, 0.10을 기점으로 지반함몰 위험도에 기여도가 급격히 상승했다고 해석 가능하다. 따라서 밀집도가 0.10 이상인 구간에 대해서는 지반함몰 사고를 관리하기 위한 적극적인 대응계획을 수립해야 할 필요가 있다.
본 연구에서는 다중분류 모델의 예측을 설명하기 위해 Class-specific SHAP 분석을 수행하였다. Class-specific SHAP 분석은 위험도 등급별 어떤 변수가 예측에 중요한 인자 활용이 가능한지 파악할 수 있어, 단일 변수 중요도보다 정교한 해석이 가능하다. Fig. 3은 전체 SHAP 값 중 고위험에 대한 SHAP 값만을 분리하여 분석하였다. 고위험 SHAP은 각 특성이 해당 샘플을 고위험으로의 기여도를 정량화한 값으로, 샘플이 최종적으로 어떤 위험도로 예측되었는지 와는 관계없이 특성이 고위험 구간의 확률을 증가 또는 감소시키는 방향성을 나타낸다. 즉, 밀집도가 지반함몰 고위험에 영향을 미치는 정도와 경향을 확인한 것이다. 분석 결과, 밀집도가 증가할수록 고위험 SHAP 값도 증가하는 경향을 보였으며, 이는 밀집도가 높을수록 모델이 해당 구간을 고위험으로 판단하도록 강하게 유도함을 의미한다.
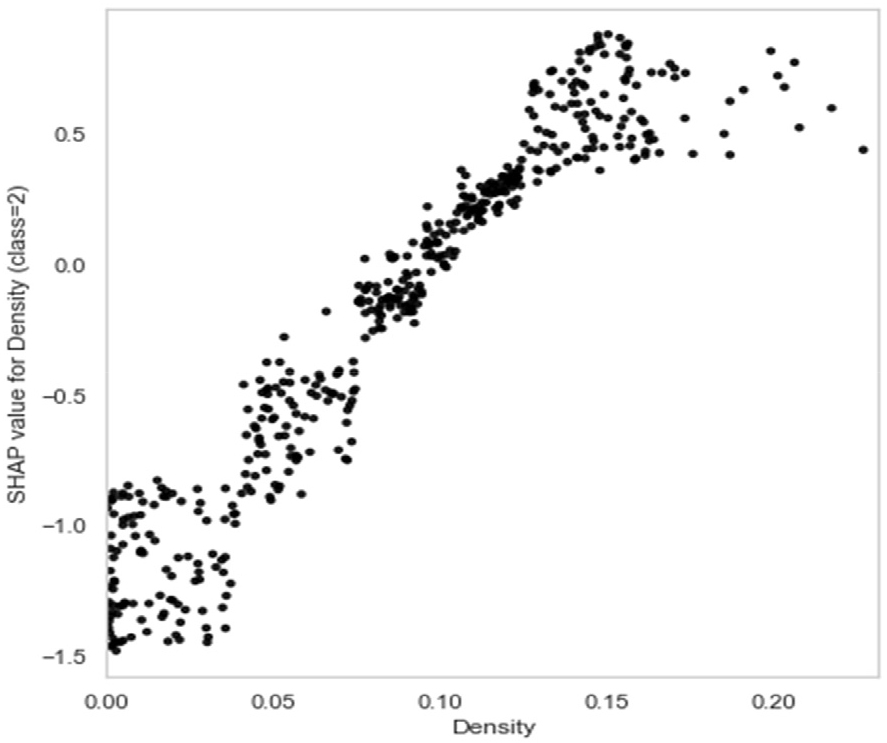
Fig. 2와 Fig. 3을 확인하면 밀집도 0.05와 0.10을 기준으로 위험도 기여 패턴이 변화하는 것을 확인할 수 있다. 따라서 0.00~0.05 구간을 저밀집도(Low), 0.05~0.10을 중밀집도(Middle), 0.1 이상을 고밀집도(High) 구간으로 선정하여 밀집도에 따른 전체 지반함몰 위험도의 분포를 확인하였다. Table 5는 그 결과를 나타낸 것이다. 저밀집도 구간에서는 대부분의 샘플이 저위험구간으로 분류되었으며, 고위험 구간으로 분류된 샘플은 극히 적었다. 중밀집도 구간에서는 중·고 위험구간으로 나타난 샘플이 증가하고 있으나, 여전히 저위험구간 샘플이 다수를 차지하고 있다. 마지막으로 고밀집도 구간에서는 각각의 지반함몰 위험구간이 혼재되어 있지만, 고위험으로 예측된 샘플 비율이 가장 높게 나타났다. 이는 저위험구간에서 고위험구간으로 분류되는 샘플이 많아지는 구간으로 확인되었다. 이러한 결과는 앞서 수행한 Class-specific Dependence 분석과 동일하게 밀집도가 증가할수록 위험 기여도가 증가한다는 경향성과 일치한다. 따라서 밀집도가 지반함몰 발생을 설명하는 핵심 독립 변수로 판단할 수 있다.
4. 결 론
본 연구는 기존 개발된 XGB 기반 지반함몰 위험도 예측 모델에 SHAP 기반 설명가능한 AI를 적용하여, 지반함몰 위험도에 영향을 미치는 핵심 인자를 정량적으로 도출하고, 대표적인 영향인자인 밀집도의 영향 방향성을 해석하였다. 분석 결과, 모델이 지반함몰 위험도를 예측하는 과정에서, 지하매설물의 밀집도를 가장 중요한 인자로 활용한 것으로 나타났다. SHAP Dependence Plot 분석에서는 밀집도가 해당 샘플이 지반함몰 위험도 예측에 대해 대체로 양(+)의 방향으로 기여하는 것으로 나타났다. Class-specific SHAP 분석에서도 밀집도가 높을수록, 지반함몰 고위험 예측에 직접적으로 기여하는 영향력이 증가함을 확인하였다. 또한, 모델이 예측한 지반함몰 위험도 예측 결과에 대한 밀집도 분포에서도 밀집도와 위험도는 비례관계인 것이 나타났다. 이러한 결과는, 지하매설물의 밀집도가 높을수록 매설 및 굴착의 반복에 따른 지반 교란과 노후화 가능성이 증가함에 따라 지반함몰 위험도가 상승한 것으로 판단된다. 따라서 밀집도를 활용하여 지하매설물 손상에 의해 발생하는 지반함몰 사고에 대한 핵심 기준지표로 활용 가능될 수 있음을 의미한다. 본 논문의 주요 결과를 요약하면 다음과 같다.
(1) SHAP 분석을 통해 지반함몰 위험도 예측모델에서 위험도 예측 시 활용한 인자의 중요도를 확인하였으며, 밀집도가 가장 주요한 영향인자로 나타났다.
(2) SHAP 분석 결과, 밀집도 변화에 따라 위험도 전환 임계값이 발생하는 것으로 나타났으며, 0.05와 0.10을 기준으로 위험도 기여도의 전환이 이루어지는 경향을 확인하였다. 이는 0.05와 0.10이 지반함몰 위험도에 영향을 미치는 임계값으로 해석 가능하다.
(3) 임계값(0.05, 0.10)을 기준으로 구분한 밀집도에 지반함몰 위험도 예측 모델이 예측한 위험도를 확인해 본 결과, 밀집도가 상승할수록 지반함몰 위험도도 높게 예측된 것으로 나타났다.
본 연구에서는 지반함몰 위험도 예측 모델에 설명가능한 AI를 추가하여 실제 지반함몰 사고에 영향을 미치는 인자를 정량화하였다. 본 연구를 통해 밀집도를 지반함몰 위험도 관리 의사결정에 주요 인자로 활용 가능하다고 판단되며, 이를 기반으로 우선중점관리구간 선정을 통한 유지관리 전략 수립에 기여할 수 있을 것으로 기대된다. 추후 연구에서는 지하수위의 변동, 굴착공사 정보 등의 정보를 정량화하고 모델에 반영하여 효율적인 지반함몰 위험도 관리 방안을 제시할 필요가 있다.
