

1. 서 론
2. 연구방법론
2.1 데이터셋 준비
2.2 YOLOv8n 모델구조
2.3 학습 설정
2.4 성능 평가 지표
3. 실험 및 결과
3.1 학습 결과 분석
3.2 앵커 탐지 성능 평가
4. 고 찰
4.1 제안 시스템의 현장 적용 가능성
4.2 한계점 및 개선 방향
5. 결 론
1. 서 론
국내 건설·토목 산업에서 지하공간 개발의 수요가 증가함에 따라 대심도 굴착 공사와 같은 토목 가시설 현장이 증가하고 있다. 토목 가시설 현장은 흙막이 구조물, 스트러트(Strut), 띠장(Wale), 앵커(Anchor) 등 다양한 가시설 부재들을 활용하여 구조물의 안정성을 보강하고 있다(Park et al., 2019). 그 중의 앵커는 지반 굴착 시 흙막이 벽체를 지지하고 토압에 저항하기 위해 설치되는 부재로 위치 및 설치 상태를 지속적으로 모니터링 하는 것을 관리 기준으로써 요구하고 있다(Ministry of Land, 2021). 현행 흙막이 가시설의 안전 관리는 크게 계측 관리와 육안점검으로 구분된다. 육안 점검은 현장 관리자가 직접 현장을 순회하며, 앵커 두부의 상태를 확인하는 방식이다. 그러나 현행 점검 방식은 현장 관리자에 의한 육안 점검에 의존하는 경우가 많아 대규모 현장이나 야간·악천 후·접근이 어려운 조건에서 점검 누락 가능성이 높고 안전 관리의 효율성 및 신뢰성에 한계가 있다. 이러한 문제를 해결하기 위해 딥러닝 기반 영상 인식 기술을 활용한 비전 모니터링 시스템의 도입이 필요하다(LOTTE E&C, 2023).
최근 컴퓨터 비전(Computer vision)과 딥러닝(Deep learning) 기술의 발전으로 건설 현장에서의 안전 모니터링을 자동화하려는 연구들이 활발히 수행되고 있다(Feng et al., 2024). 이 중 YOLO(You Only Look Once) 계열의 실시간 객체 탐지 알고리즘은 높은 탐지 정확도와 빠른 추론 속도를 바탕으로 건설 현장의 개인보호구(PPE) 착용 여부, 중장비 감지, 위험 구역 침입 감지 등 다양한 안전 관련 응용에 적용되어 왔다(Kim et al., 2023; Feng et al., 2024; Zhang et al., 2024). Hayat & Morgado-Dias(2022)는 YOLOv5x 모델을 활용한 안전모 자동 탐지 시스템을 구축하여 92.44 %의 mAP를 달성하였으며, 저조도 환경에서도 우수한 탐지 성능을 나타냈다(Hayat & Morgado-Dias, 2022). 또한 Park et al.(2023)은 YOLOv5 기반의 SOC-YOLO를 제안하여 복잡한 건설 현장에서 소규모 겹침 작업자를 탐지하는 문제를 해결하였으며, 소형 객체에 대하여 평균 정밀도(Average Precision)를 81.26 %에서 84.63 %로 향상시켰다(Park et al., 2023). Zhang & Zhang(2022)은 건설 현장 모니터링 및 굴삭기 활동 분석 시스템을 구축하여 YOLOv5 모델이 추론 속도를 Faster R-CNN, YOLOv3 모델 대비 최대 34배까지 향상시킬 수 있음을 보고하였다(Zhang & Zhang, 2022).
본 연구에서 활용한 YOLOv8은 2023년 Ultralytics에 의해 공개되어 이전 버전 대비 향상된 백본 구조, 앵커-프리(Anchor-free) 탐지 헤드, 개선된 손실 함수를 통해 탐지 정확도와 속도를 동시에 향상시킨 객체 탐지 프레임워크이다(Jocher et al., 2023; Thakur et al., 2023; Varghese & Sambath, 2024). Varghese & Sambath(2024)에 따르면 YOLOv8은 주의 메커니즘(Attention mechanism)과 동적 합성곱(Dynamic convolution)을 도입하여 소규모 객체 탐지 성능을 개선하였으며, 벤치마킹을 통해 탐지 정확도와 추론 속도를 보고하였다(Varghese & Sambath, 2024). 그 중 YOLOv8n(Nano) 모델은 가장 경량화된 버전으로, 파라미터 수와 연산량이 적어 엣지 디바이스 환경에서의 실시간 추론에 적합한 것으로 보고되고 있다(Çiftçi et al., 2024; Zhexebay et al., 2025).
토목 구조물을 대상으로 한 딥러닝 기반 탐지 연구도 다양하게 이루어지고 있다. Seo et al.(2022)는 YOLOv3 알고리즘을 활용하여 도로 공사 구간의 임시 교통 통제 장치를 98 % 이상의 정확도로 탐지하는 시스템을 개발하였다. 이는 자율 안전 점검의 첫 단계로 활용될 수 있음을 제시하였다(Seo et al., 2022). Duan et al.(2022)은 건설 현장의 딥러닝 응용을 위한 대규모 이미지 데이터셋 SODA를 구축하였으며, 작업자, 자재, 기계, 레이아웃의 15개 클래스에 대해 YOLOv3/v4를 적용하여 최대 mAP 81.47 %를 달성하였다(Duan et al., 2022). 그러나 토목 가시설 현장의 앵커와 같이 특정 구조 부재를 대상으로 하는 탐지 연구는 아직 초기 단계에 머물러 있으며, 관련 데이터셋의 부재와 가시설 현장마다 조명, 원근, 겹침 등 시각적 환경이 매우 달라 안정적인 객체 탐지 성능을 확보하기 어려운 현장 환경으로 인해 선행 연구가 매우 제한적이다.
본 연구에서는 토목 가시설 현장의 앵커를 자동으로 탐지하는 실시간 안전 관리에 적용하기 위해 YOLOv8n 모델을 활용하여 국내 실제 굴착 현장 데이터를 기반으로 모델을 학습·평가하였다. 본 연구의 주요 기여는 첫째, 오픈 소스 데이터가 아닌 실제 토목 현장의 다양한 조도, 각도 등을 반영한 앵커 특화 이미지를 직접 수집하여 데이터셋을 구축하였다. 둘째, YOLOv8n 모델을 전이 학습(Transfer learning) 및 미세 조정(Fine-tuning)하여 앵커 탐지에 특화된 경량 모델을 개발하였다. 셋째, 다양한 현장 조건(조명, 각도 등) 에서의 탐지 성능을 평가하고 한계점과 개선 방향을 제시하였다.
2. 연구방법론
2.1 데이터셋 준비
본 연구의 데이터셋은 국내 도심지 굴착 가시설 현장에서 직접 촬영한 이미지를 기반으로 구축하였다. 촬영 장비는 DJI사의 Mavic 3 Enterprise를 사용하였다. 수집 과정에서 앵커 구조를 포함할 수 있도록 앵커에서 2~3 m 떨어진 거리에서 촬영하였고, 다양한 조도(주간·흐린 날씨), 촬영 각도(정면·측면·상부·하부)를 포함하도록 수집하였다. 데이터셋을 수집한 UAV 하드웨어는 Fig. 1에 나타냈다.
UAV를 통해 가시설 현장에서 수집된 이미지에 대해 어노테이션(Annotation) 작업을 수행하여 앵커 두부를 바운딩 박스로 어노테이션하였다. 어노테이션 도구는 오픈 소스 브라우저 기반 어노테이션 플랫폼인 CVAT(Computer Vision Annotation Tool)을 활용하였으며, 앵커 두부가 잘린 경우에는 탐지 대상에서 제외하였다. 본 연구에서는 데이터 분할 과정에서 발생할 수 있는 특정 데이터의 누락이나 샘플링 편향을 방지하기 위해 난수 시드를 적용한 무작위 샘플 분할(Random Sample Splitting) 방식을 적용하였다. 이에 따라 학습(Training), 검증(Validation), 테스트(Test) 세트를 각각 80 %, 10 %, 10 % 비율로 분할하였다. 최종 학습 데이터셋은 약 6,200장으로 데이터셋의 구성은 Table 1에 요약했다.
Table 1.
Dataset configuration
| Training | Validation | Test | Total | |
| Images | 4,964 | 620 | 621 | 6,205 |
| Ratio | 80% | 10% | 10% | 100% |
2.2 YOLOv8n 모델구조
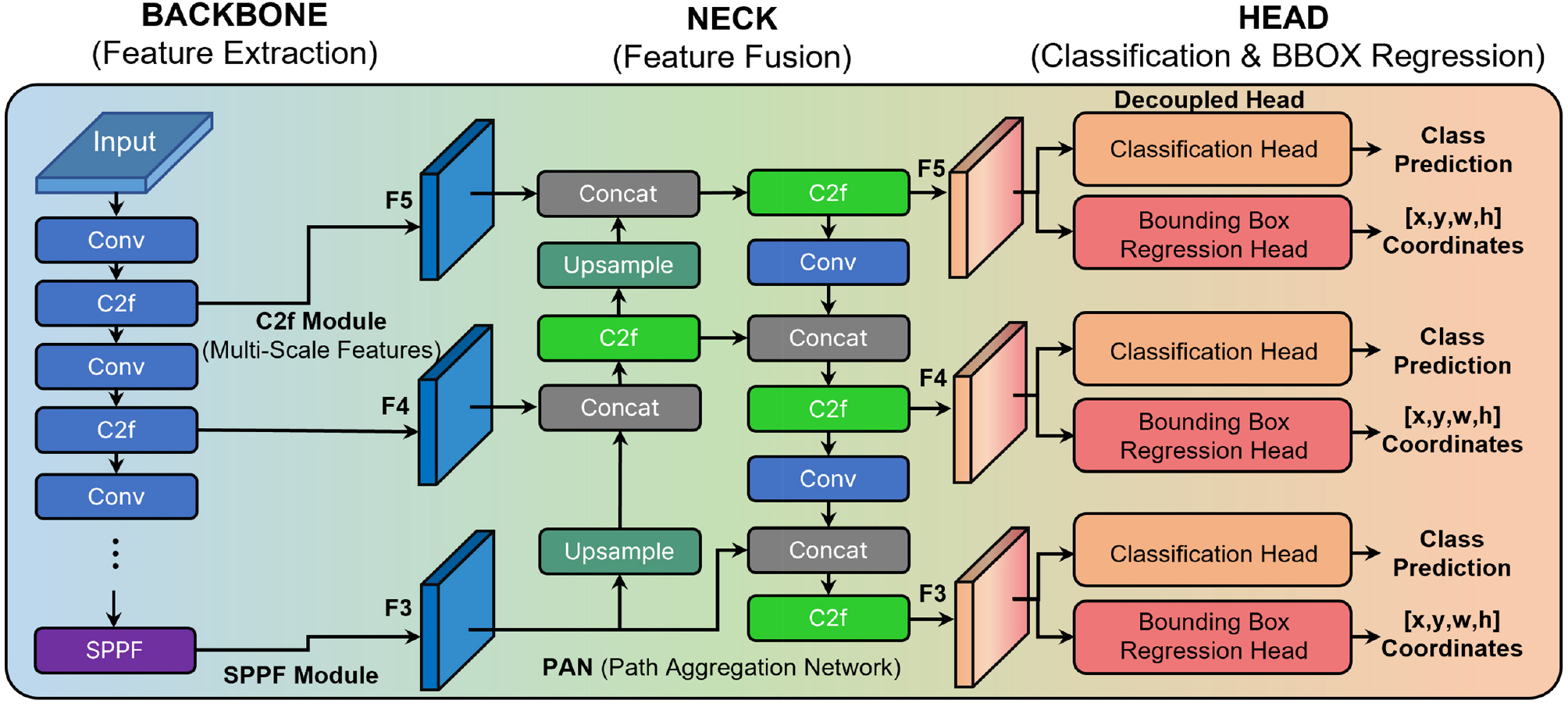
YOLOv8n은 Ultralytics가 2023년 공개한 YOLOv8 variants 중 가장 경량화된 모델로써 파라미터 수 약 3.2 M, 연산량 약 8.7 GFLOPs(Giga Floating-point Operation Per Second)의 소형 모델이다. YOLOv8 variants의 각 사양은 Table 2에 나타냈다. YOLOv8은 백본(Backbone), 넥(Neck), 헤드(Head)의 세 부분으로 구성된다. 백본은 C2f(Cross-Stage Partial with feature fusion) 모듈과 SPPF(Spatial Pyramid Pooling Fast) 모듈을 기반으로 다중 스케일 특징 추출을 수행한다(Mien et al., 2025). 특히, YOLOv8은 이전 모델들과 달리 미리 정의된 앵커 박스에 의존하지 않는 Anchor-free 기반 탐지 방식을 채택하였다. 여기서 YOLOv8의 Anchor-free 방식은 탐지 알고리즘상의 사전 정의된 박스(Anchor Box)를 배제하는 기술적 용어로, 본 연구의 연구 대상인 지반 구조물 그라운드 앵커(Ground Anchor)와는 용어상 서로 독립적인 개념이다. 이를 통해 사전 정의된 박스(Anchor Box) 설정을 위한 복잡한 하이퍼 파라미터 최적화 과정을 배제함으로써 모델 연산의 효율성을 높이고 가변적인 객체의 크기와 종횡비 변화에 대한 탐지 유연성을 확보하였다. 넥은 PAN(Path Aggregation Network) 구조로 다양한 스케일의 특징을 융합한다. 헤드는 분리 탐지 구조(Decoupled head)로 이루어져 분류(Classification)와 위치 회귀(bounding box regression)를 독립적으로 수행하여 후처리 복잡도를 낮추고 추론 속도를 향상시켰다. YOLOv8 모델 구조는 Fig. 2에 나타냈다.
Table 2.
YOLOv8 variants specification
2.3 학습 설정
본 연구에서는 Common Object in Context(COCO) 데이터셋으로 사전 학습된 YOLOv8n 가중치를 바탕으로 하는 전이 학습(Transfer learning)을 수행하였다. 본 연구에서 활용된 워크스테이션은 Table 3에 나타냈다.
Table 3.
Hardware specification
| Component | Specification |
| CPU | AMD Ryzen 3960X 24-core (48 CPUs) |
| GPU | NVIDIA RTX 5080 (VRAM 16 GB) |
| RAM | 128 GB |
| OS | Windows 10 |
하드웨어 성능을 고려하여 적용된 미세 조정 학습 하이퍼파라미터는 Table 4에 나타냈다. 특히, 배치 크기(Batch size)는 사용된 워크 스테이션의 VRAM 용량과 학습 효율을 고려하여 16으로 지정하고, 야외 건설 현장의 복잡한 배경에서 앵커 헤드의 세부 특징을 충분히 학습하기 위해 통상적인 미세 조정(Fine-tuning) 기준인 50 에포크(Epoch)보다 큰 100 에포크를 적용하였다. 동시에 조기 종료(Early stopping)는 patience 50으로 설정하여 과적합을 방지하였다. 입력 이미지 크기(Input size) 640×640픽셀, 옵티마이저(Optimizer)는 탐지 모델에 주로 채택되는 경사하강법(Stochastic gradient Descent, SGD)를 사용하였다. 또한, 학습 과정에서 별도의 증강 기법을 설계하는 대신 YOLOv8 프레임워크에 내장된 표준 설정(Standard Protocol)을 적용하였다. 주요 설정값은 Mosaic(1.0), HSV jitter(H:0.015, S:0.7, V:0.4), Horizontal Flip(0.5)이며, 마지막 10 에포크 구간에서는 Mosaic 증강을 비활성화(Close Mosaic)하였다(Jocher et al., 2023).
Table 4.
Fine-tuning hyperparameter configuration
| Parameter | Value |
| Epochs | 100 |
| Batch Size | 16 |
| Input size | 640×640 px |
| Optimizer | SGD |
| Warm-up Epochs | 3 |
| Early Stopping (Patience) | 50 |
2.4 성능 평가 지표
모델의 탐지 성능과 연산 효율성을 다음과 같은 지표를 활용하여 평가하였다. 탐지 성능은 정밀도(Precision), 재현율(Recall), F1 점수(F1-score), mAP@50, mAP@50:95, Frame Per Ssecond(FPS)를 적용하였다. F1 점수는 정밀도와 재현율의 조화 평균으로 두 지표를 종합적으로 평가하는 지표다. mAP@50은 IoU(Intersection over Union) 0.5 기준의 평균 정밀도(Average Precision)를 의미하며, mAP@50:95는 IoU 0.5에서 0.95 사이의 평균 정밀도를 나타내는 평가 기준이다. 모델의 탐지 속도는 추론 지연시간(Inference Latency)과 초당 처리 가능한 프레임 수(FPS)를 통해 평가하였다.
여기서, TP는 모델이 정탐지한 True Positive, FP는 모델이 객체를 오탐지한 False Positive, FN은 모델이 객체를 미탐지한 False Negative를 의미한다.
3. 실험 및 결과
3.1 학습 결과 분석
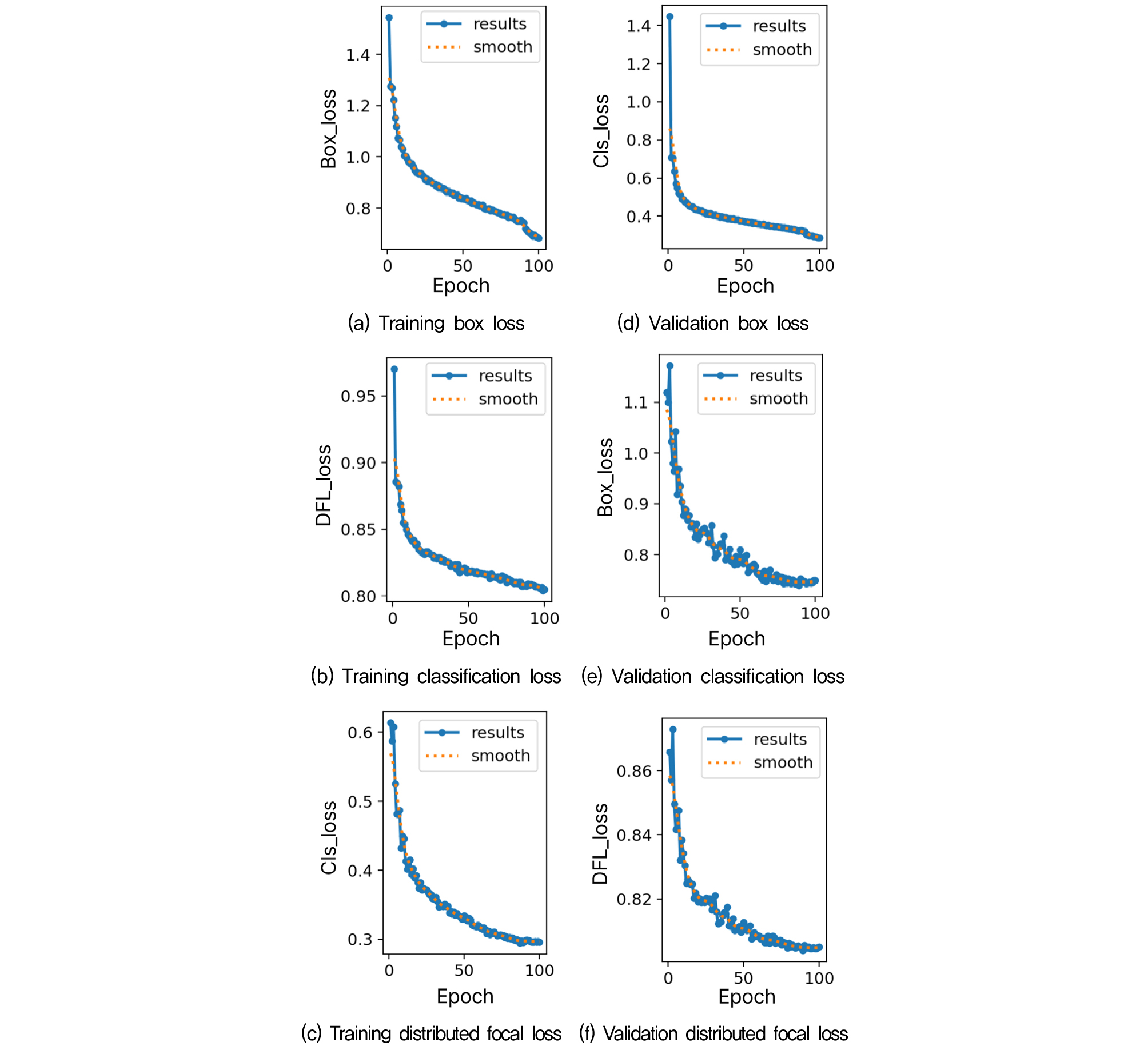
YOLOv8n 모델의 학습 과정에서 학습 손실(Training loss)과 검증 손실(Validation loss)은 Fig. 3에 나타냈다. 에포크가 증가함에 따라 감소하는 추세를 보였다. 구체적으로, 박스 손실(Bounding Box loss, Box_loss), 분포 초점 손실(Distribution Focal loss, DFL_loss)의 지속적인 감소는 앵커 두부를 정밀하게 회귀하는 능력이 학습 종료 시점까지 꾸준히 향상됨을 나타낸다. 또한 분류 손실(Classification loss, Cls_loss)은 학습 초기 단계에서 급격히 감소한 후 안정화되었는데, 이는 모델이 가시설 배경으로부터 앵커 객체의 특징을 빠르고 정확하게 학습했음을 의미한다. 검증 손실이 학습 손실과 유사한 수준으로 감소한 점은 모델이 학습 데이터에 과적합(Overfitting) 되지 않고 검증 데이터에 대해서도 높은 일반화 성능을 확보하였음을 의미한다.
3.2 앵커 탐지 성능 평가
테스트 데이터셋에 대한 탐지 성능 평가 결과, 정밀도 0.996, 재현율 0.996을 기록하였으며, mAP@50은 0.995의 성능을 달성하였다. mAP@50:95 기준으로도 0.827의 성능을 보여 다양한 IoU에서 탐지 능력을 입증하였다. 추론 속도는 단일 이미지 기준 2.765 ms로, 361.699FPS를 기록했다.
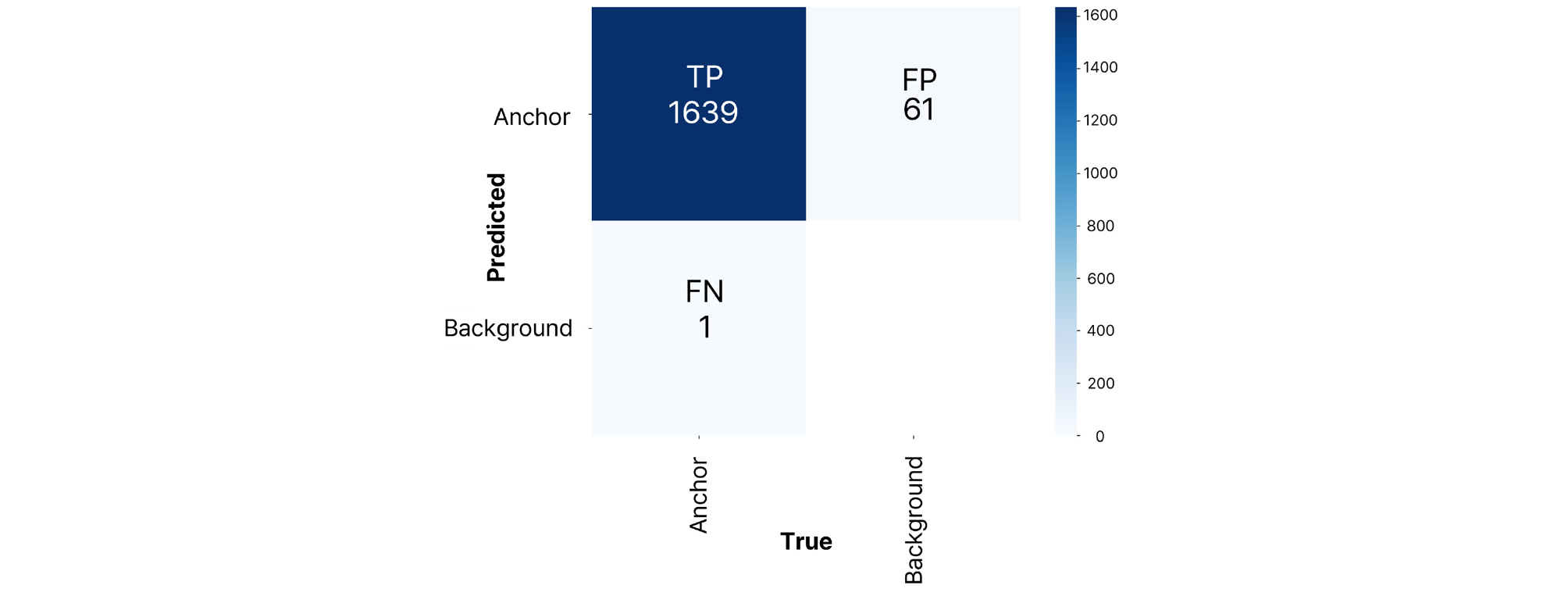
탐지 모델의 혼동 행렬(confusion matrix) 결과는 Fig. 4에 나타냈다. 혼동 행렬 분석 결과, 탐지 성능 평가와 같이 배경(Background)을 앵커로 오탐지(False Positive, FP)한 사례가 61건 발생하였으며, 미탐지(False Negative, FN) 사례는 1건 발생하였다.
4. 고 찰
4.1 제안 시스템의 현장 적용 가능성
본 연구에서 제안한 YOLOv8n 기반 앵커 탐지 시스템은 워크스테이션에서 기록한 이미지당 총 지연시간 2.765 ms (361.699FPS)이며, mAP@50 0.995의 충분한 탐지 정확도를 기록하였다. 이는 저사양 엣지 디바이스 적용에도 여유 성능을 확보할 수 있는 수준으로써 엣지 디바이스 배포 시 충분한 적용 가능성이 있음을 시사한다(Table 5 참조). 특히 YOLOv8n의 경량화된 구조는 현장에 설치된 CCTV나 드론(UAV), 또는 태블릿·스마트폰과 같은 모바일 장치에 모델을 직접 탑재하는 시나리오에 적합하여 접근이 제한된 구역에서 실시간 모니터링이 가능할 것으로 판단된다.
Table 5.
Detection performance of the YOLOv8n model
| Model | Metric | Value |
| YOLOv8n | mAP@50 | 0.995 |
| mAP@50:95 | 0.827 | |
| Precision | 0.996 | |
| Recall | 0.996 | |
| F1-Score | 0.996 | |
| Latency (ms) | 2.765 | |
| FPS | 361.699 |
4.2 한계점 및 개선 방향
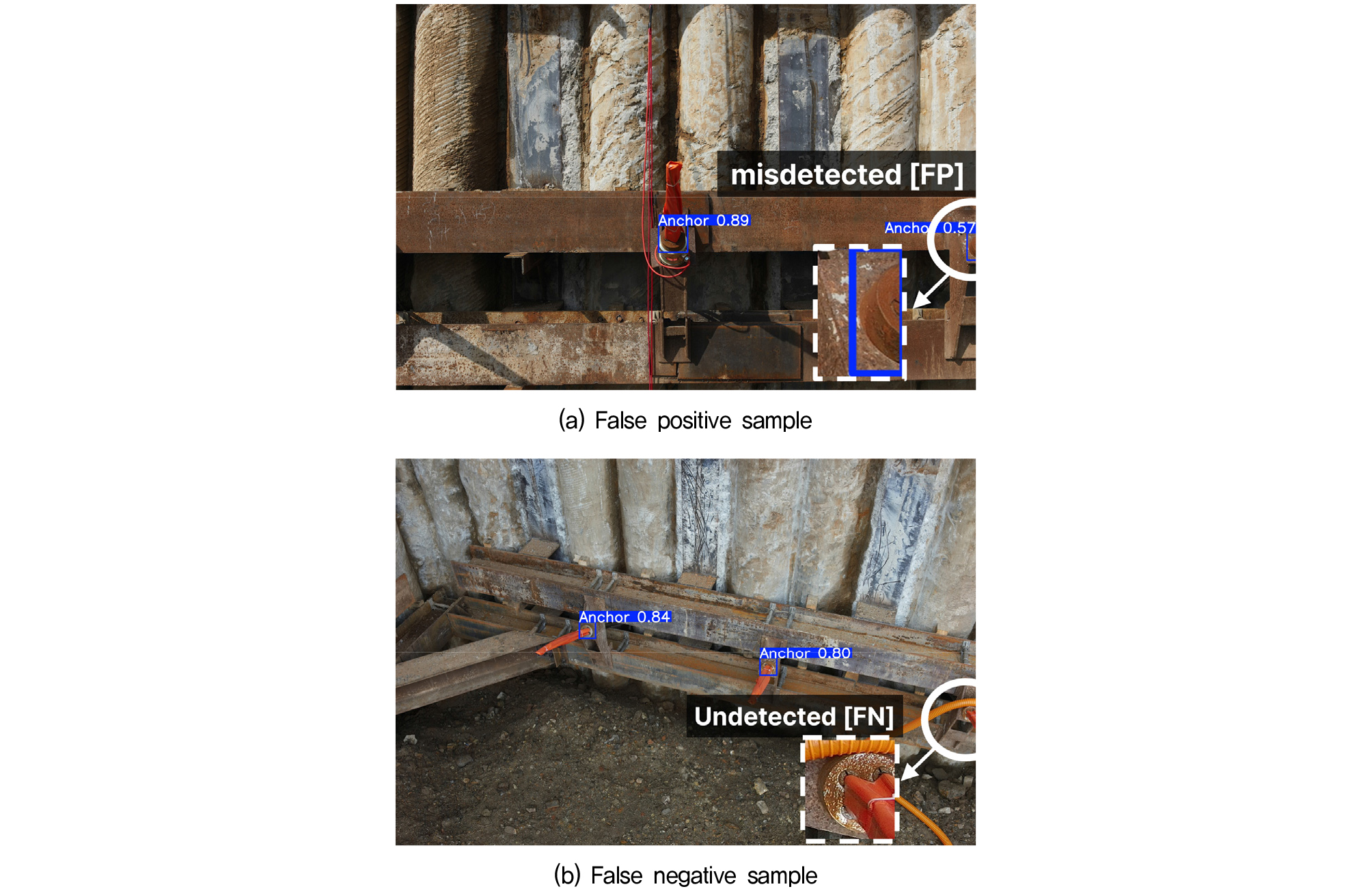
YOLOv8n의 높은 성능 평가 결과에도 불구하고 본 연구의 주요 한계점은 다음과 같다. 첫째, 한 현장에서 취득한 데이터셋은 배경과 객체의 특징이 매우 유사해 학습 환경과 테스트 환경의 차이가 거의 없다. 이는 다른 현장에서의 앵커 유형을 충분히 탐지하지 못할 가능성이 있다. 향후 여러 현장에서의 다양한 앵커 유형 포함한 데이터셋 구축이 필요하다. 둘째, UAV를 통한 데이터 수집에 따른 오류 발생이 지배적임을 나타냈다. Fig. 5는 지배적인 오류 발생 유형을 나타낸 그림이다. 혼동 행렬 결과에서 나타난 FP와 FN에 해당하는 이미지 분석 결과, Fig. 5(a)에 나타낸 바와 같이 모든 FP에 대해 UAV로 촬영한 영상을 이미지 단위로 자르다 보니 잘린 앵커를 탐지하였다. 올바른 탐지라고 할 수 있지만, 어노테이션 과정에서 잘린 앵커는 앵커로 취급하지 않았기에 오탐지로 평가되었다. 1건의 FN은 Fig. 5(b)에 나타낸 바와 같이 앵커 주변에 공사 현장 구조물이 앵커 헤드에 근접해 있어 학습 환경에 없는 난이도 있는 객체이기 때문에 미탐지한 것으로 분석된다. 이러한 오류 발생을 개선하기 위해 추후에는 프레임에 잘린 앵커가 포함된 이미지는 전처리를 통해 필터링하는 과정을 적용할 필요가 있다. 마지막으로 모델 성능 향상을 위한 개선 방향으로 YOLOv8 모델의 모든 variant를 비교·분석하여 속도-정확도의 최적 모델 선정, 고화질 이미지 내 소형 객체(앵커)의 탐지 정확도 개선을 위한 YOLOv8 모델 구조 수정 등을 고려할 수 있다.
5. 결 론
본 연구에서는 토목 가시설 현장에서 앵커를 자동으로 탐지하기 위해 경량 딥러닝 객체 탐지 모델인 YOLOv8n을 적용 및 학습·평가하였으며, 도출된 주요 결론은 다음과 같다.
(1) 국내 굴착 현장에서 UAV를 통해 수집한 이미지로 앵커 탐지 전용 커스텀 데이터셋을 최초로 구축하여 실제 가시설 현장의 조명, 각도 조건을 고려하여 모델의 일반화 성능을 향상시켰다.
(2) YOLOv8n 모델은 mAP@50 0.995, mAP@50:95 0.827, 추론 시간 2.765 ms/장(약 360 FPS)를 기록하여 현장 CCTV 또는 모바일 장치를 통한 실시간 앵커 모니터링에 적용될 수 있는 가능성을 실험적으로 입증하고, 현장 안전 관리 자동화를 위한 비전 기반 모니터링 시스템의 기반을 마련하였다.
(3) UAV를 통한 데이터 수집과정에서 높은 FPS로 인해 이미지의 중복성이 매우 높은 것을 확인하였다. 향후 모델의 과적합(Overfitting)을 방지하기 위해 데이터 중복성 제거를 위한 전처리 과정의 필요성을 확인하였다.
(4) 향후 연구에서는 조명, 각도 이외의 거리, 높이 등의 다양한 환경에서 수집된 데이터셋을 구축하고, 앵커의 상태 평가로 이어지는 파이프라인 시스템으로 확장할 계획이다. 더하여, 야간, 악천후 조건등의 비전 기반 취약성 조건에 따른 탐지 성능 변화를 통해 비전 기반 모니터링에 취약한 요소가 무엇인지 분석 및 최적화할 것이다. 또한, 고성능 워크스테이션 기반이 아닌 스마트폰, 드론 컨트롤러 등 엣지 디바이스 환경에서의 추후 연구를 통해 실시간성의 구동 성능을 분석 및 최적화할 계획이다.
