

1. 서 론
2. 머신러닝 알고리즘
2.1 Logistic regression
2.2 Random Forest
2.3 Extremely randomized tree
2.4 XGBoost
3. 급경사지의 붕괴위험성 평가
3.1 대상 급경사지 현황
3.2 급경사지 데이터의 특성
3.3 분석에 사용된 붕괴데이터
4. 비탈면 조사자료의 적합성 검증
4.1 교차검증
4.2 평가지표
5. 비탈면의 조사결과에 대한 머신러닝(ML) 학습
6. 결 론
1. 서 론
급경사지 붕괴는 불특정한 시간과 공간에서 피해를 유발하여 재해를 예방하고 안전을 확보하기 위해서는 비탈면의 안정에 영향을 줄 수 있는 인자를 평가하고 사전적으로 관리할 필요가 있다. 이를 위해 불안정한 급경사지를 붕괴위험 구간으로 특정하고 정기적으로 관리하는 방법을 시행하고 있으며, 붕괴위험구간을 설정하거나 급경사지의 위험성 평가를 목적으로 ‘산사태 위험지 평가표’나 ‘재해위험도 평가표’ 등이 개발되어 적용되고 있다. 이와 같은 평가표는 급경사지의 위험성과 관련된 붕괴위험성과 사회적 영향도 등의 다양한 인자로 구성되어 있다. 위험급경사지를 예측하기 위해서는 평가기준의 정립과 평가인자의 결정이 매우 중요하며, 평가표의 개발과 개선을 위해서 많은 연구자들은 다양한 응용통계기법을 활용하는 상황이다. 확률론적 분석에 의한 통계적인 기법은 비탈면 안정과 관련된 다양한 자료를 기반으로 확률론적이론을 도입함으로써 비탈면의 위험도를 예측하는 방법으로 로지스틱회귀분석이나 인공신경망을 사용하거나 위성영상을 활용하는 연구가 수행되어 왔으며(Nam et al., 2020), 전문가그룹의 설문조사를 통한 AHP분석을 이용한 모델들이 이용되어 왔다.
또한 기존의 모델들은 위험지역을 선정하기 위해 현장조사와 일부 실내시험 결과를 적용하고 있으나, 이진분류(붕괴 및 미붕괴)를 사용함에 있어 생성과 샘플링에 한계를 보이는 것으로 보고(Nam & Wang, 2019)되고 있으며, 붕괴지역에 대한 현장조사 자료를 적용한 모델 연구가 부족한 상황으로 발표하고 있다(Nam et al., 2020).
최근에는 machine learning 기법을 활용한 연구가 진행되고 있는 상황으로 자동화된 머신러닝인 AutoML은 머신러닝과 딥러닝 모델을 구축하는데 있어 기술력을 갖춘 데이터 과학자란 필요조건을 극복하기 위하여 개발되었으며, 현존하는 대부분의 예측 모델을 적용해 보고 최적의 모형을 선택한 바 있다(Nagarajah & Poravi, 2019). 또한 Nam et al.(2020)은 현장조사 결과를 이용하여 AutoML 모델링을 구축하고 검증였으며, 비탈면 불안정에 영향을 미치는 요인들에 대한 변수 중요도를 산정한 바 있다. Ma & Yun(2022)은 machine learning의 일환인 다층 퍼셉트론(multilayer perceptron) 신경망을 통해 사면의 안전율과 임계활동면의 관계를 도출하였으며, 이를 통해 원호 파괴면을 예측하고 위험지역을 결정할 수 있는 결과도 제시되고 있다.
따라서 본 연구에서는 전국의 붕괴가 발생되지 않은 7,791개 미붕괴 급경사지와 붕괴가 발생된 91개 붕괴 급경사지를 대상으로 현장조사를 수행하고 조사내용을 분석하였다. 분석에 사용된 데이터는 ‘재해위험도평가’항목으로 점수에 영향력을 가지는 붕괴위험성을 인지할 수 있는 기하형상, 지형, 지질, 풍화상태, 시설현황 및 강우 등 보호대상시설에 재해를 유발하는 다수의 인자들로 구성되어 있다.
이와 같이 수집된 재해위험도평가 데이터를 붕괴지와 미붕괴지로 분류하고 붕괴를 유발하는 인자에 대한 분석을 수행하였으며, 조사결과를 활용한 붕괴발생 예측모델을 결정하기 위해 Logistic Regression, Random Forest, Extra trees, XGBoost의 네 가지 머신러닝 알고리즘을 비교하고 분석을 수행하였다.
2. 머신러닝 알고리즘
본 연구에서는 범주형 데이터의 특성상 결정트리 기반의 앙상블 기반 알고리즘이 범주형 데이터의 구분을 직관적으로 처리하기 때문에 관계를 파악하기 유리하다는 Kim & Kim(2024)의 연구결과를 반영하여 아래와 같은 앙상블 기반 알고리즘을 분석에 적용하였다.
2.1 Logistic regression
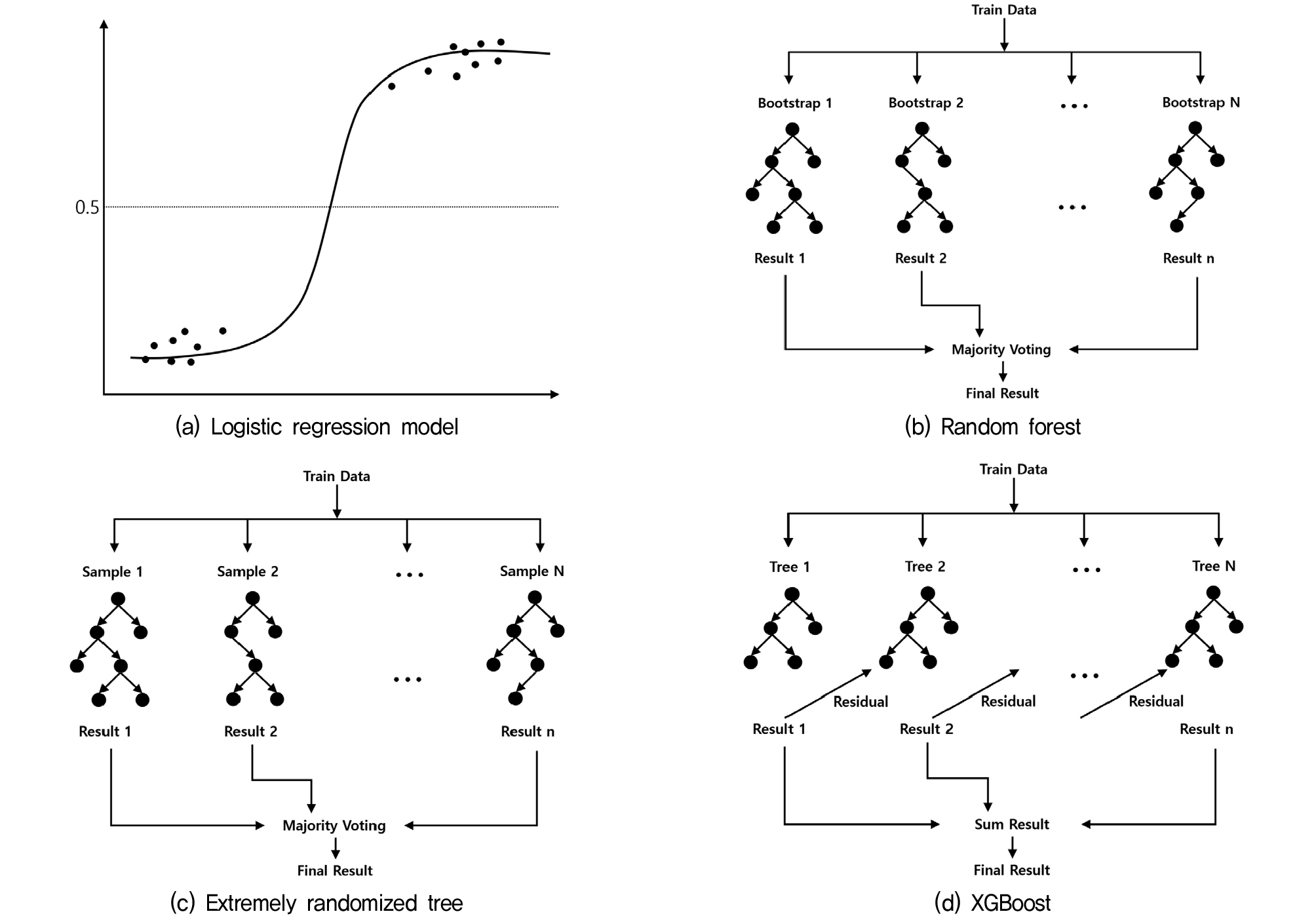
Logistic regression은 종속 변수가 두 가지 클래스 중 하나를 갖는 경우에 사용하는 대표적인 통계적 분류 모형이다. 본 모델은 먼저 독립변수들의 선형 결합으로 로그 오즈(log odds)라 불리는 값을 계산하는데, 여기서 오즈란 사건이 발생할 확률(p)과 발생하지 않을 확률(1-p)의 비를 의미하고 오즈에 로그함수를 취한 것을 로그오즈라고 한다. 이렇게 구한 로그 오즈를 모든 실수 값을 0과 1사이로 변환해 주는 시그모이드(sigmoid) 함수를 통해 0과 1사이의 확률값으로 변환한다. 확률값은 0.5를 기준으로 두 클래스로 분류한다.
2.2 Random Forest
의사결정나무(decision tree)는 노드(node)라고 부르는 분할 지점을 연속해서 나누며, 예측을 수행한다. 여기서 하나의 노드는 분할 전후에 클래스가 얼마나 섞여 있는지를 나타내는 불순도 개념을 기반으로 생성되며, 불순도가 낮을수록 같은 클래스끼리 모여 있음을 의미한다. 결정 트리의 분할 기준으로 불순도를 측정하는 지표인 지니 계수나 엔트로피를 사용한다. 지니 계수와 엔트로피는 정보의 불확실성을 측정하여 분할 전후의 정보 이득을 최대화하는 변수를 선택한다.
Random Forest 알고리즘은 여러 의사결정나무를 결합하여 예측 성능을 향상시키는 앙상블(ensemble) 기법이다. 분류 문제의 경우, 각각의 모형들이 예측한 결과 중 가장 많이 나온 값을 예측결과로 선택하는 다수결 방식을 사용한다. 단일 의사결정나무로는 과적합의 위험이 있지만, Random Forest는 부트스트랩 샘플과 무작위로 선택된 변수를 사용해 생성된다. 이러한 방식은 개별 모형의 상관성을 낮추어 모델의 예측 성능을 향상시키고 과적합을 줄이는 효과가 있다.
2.3 Extremely randomized tree
Extra Trees(Extremely randomized tree)는 Random Forest 모델과 유사하게 여러 개의 의사결정나무를 결합하여 다수결 투표를 통해 최종 결과를 도출하는 앙상블 학습 기법이다. 하지만 Extra Trees는 Random Forest와 달리 부트스트랩 샘플이 아닌 전체 학습 데이터를 사용한다는 점에서 차이가 있다. 또한, 의사결정나무에서 변수뿐만 아니라 분할 기준값까지 무작위로 선택한다. 이런 차이점들은 편향과 분산을 줄이는 데에 기여하고, 분할 기준을 찾는 비용을 크게 줄여 대규모 데이터셋에서도 빠르게 학습할 수 있게 만든다. 이처럼 무작위성을 극대화하는 방식은 학습 속도를 높이며, 학습 데이터에 대한 과적합을 방지하는데 유리하다.
2.4 XGBoost
XGBoost(Extreme Gradient Boosting) 알고리즘은 의사결정나무를 기반으로 하는 앙상블 학습 방법으로 약한 학습기를 순차적으로 학습시켜 오차를 반복적으로 보완하는 부스팅(boosting) 방식을 따른다. 각 단계에서는 이전 모델이 틀린 예측에 더 큰 가중치를 부여하고, 해당 오차를 줄일 수 있도록 다음 모델이 학습된다. XGBoost는 모델이 지나치게 복잡해지는 것을 방지하기 위해 손실 함수에 규제 항을 포함하고 있다. 또한 의사결정나무 분할 기준에서 얻는 정보 이득이 충분하지 않을 경우 분할을 제한하는 방식의 가지치기를 수행하여 모델이 복잡해지는 것을 방지하고 모델의 일반화 성능을 향상시키는데 기여한다. XGBoost는 빠른 속도와 정확도를 장점으로 하여 다양한 분야에서 뛰어난 성능을 보이고 있다.
3. 급경사지의 붕괴위험성 평가
3.1 대상 급경사지 현황
본 연구는 2022년~2024년에 수행된 전국 급경사지 실태조사 자료 중 미붕괴 비탈면 전라남도 1,434, 전라북도 1,327, 충청남도 1,291, 경상북도 970, 강원도 711, 경기도 618, 경상남도 621, 충청북도 417, 부산 100, 대구 76, 서울 53, 대전 45, 세종 24, 인천 20, 광주 16, 제주도 6개소 총 7,791개소에 대한 자료를 대상으로 수행하였다. 붕괴 비탈면은 전국에서 최근 붕괴가 발생한 91개소(Fig. 2)의 현장조사 자료를 활용하였다. 논문에 사용된 붕괴 비탈면 자료는 암반사면이 69%(69개소), 토사사면은 20%(20개소)인 것으로 나타났고 미붕괴비탈면은 암반사면이 62%(5,418개소), 토사사면이 30%(2,719개소)인 것으로 나타났다.
3.2 급경사지 데이터의 특성
본 연구에서는 비탈면의 재해위험성을 판단하기 위해 행정안전부와 지방자치단체에서 수행한 실태조사 및 재해위험도 평가 결과를 기본적인 데이터로 사용하였으며, 조사내용은 일반정보(수직고, 길이, 경사 등)와 지반정보(결함인자, 피해인자 등), 토석류발생가능성 및 관리방안 등으로 구성되어 있다. 또한 재해위험도평가표는 붕괴위험성 항목(지형, 지질, 시설, 강우)과 사회적영향도 항목(보호대상시설, 이격거리) 및 보정점수로 구성되어 있다.
비탈면의 안정성을 평가하기 위해 수행된 현장조사 자료 중 학습에 사용된 중요 인자는 지형(경사각, 비탈면최대높이, 횡단형상), 지반지질(지반변형, 절리방향, 풍화도, 붕괴이력), 시설(표면보호 상태), 강우(지하수·배수 상태)로 붕괴 위험인자로써 예측 모델 적용 시 변수로 활용하였다.
미붕괴비탈면에 대한 분석결과(Fig. 3), 재해위험도평가 결과는 C등급(80.4%), B등급(12.9%)의 순으로 나타났으며, 암반비탈면이 61.4%, 토사가 30.8%를 보이고 횡단구조는 직선형(67.3%)과 요철형(16.4%)이 주를 이루고 있다. 또한 대부분의 비탈면이 길이 100~150m, 높이 5~24m의 범위를 보이는 것으로 조사되었고 53.8%가 45~63°의 경사각을 보이고 있으며, 풍화도는 중간풍화가 51%, 심한풍화가 35.6%인 것으로 나타났다.

붕괴비탈면(Fig. 4)의 재해위험도평가 결과는 D등급(60%), C등급(37.8%)의 순으로 나타났으며, 암반비탈면이 69.9%, 토사가 27.9%를 보이고 횡단구조는 요철형(61.1%), 하부이탈형(13.3%)이 주를 이루고 있다. 또한 붕괴 비탈면은 높이 5~24m(96.4%)의 범위와 경사각 63° 이상(26.4%)의 범위가 가장 큰 것으로 나타났고 풍화도는 중간풍화가 58.2%, 심한풍화가 41.8%인 것으로 나타났다.

분석결과, 붕괴가 발생된 급경사지는 대부분 D등급 비중이 높으나 C등급의 약 38%로 잠재적인 요인에 따른 붕괴도 다수 발생되고 있는 것으로 판단된다. 붕괴비탈면의 구성비율은 암반 비중이 높고 횡단형상 중 요철형 비중이 크게 증가되는 양상을 확인할 수 있으며, 중소규모의 고경사(>63°) 비탈면의 붕괴가 큰 것으로 나타났다. 특히 비탈면의 붕괴가 절리의 방향과 상당히 밀접한 관계를 가지고 있음을 확인할 수 있다.
3.3 분석에 사용된 붕괴데이터
Table 1은 급경사지 붕괴의 예측을 위해 사용한 데이터로 크게 재해위험도평가 점수에 영향력을 가지는 비탈면 제원 요인, 토사지반, 암반지반, 구조물에 불안정을 유발할 수 있는 다양한 위험인자들과 평가점수에 영향력을 가지는 요인들로 구성되어 있다. 예측 목표인 비탈면붕괴는 0(급경사지 붕괴 미발생)과 1(급경사지 붕괴 발생)로 구분되어 있으며, 0인 데이터가 7,791개, 1인 데이터가 91개로 비탈면붕괴가 발생하지 않은 데이터가 약 98%인 불균형 데이터를 연구에 활용하였다.
Table 1.
Major factor using analysis
미붕괴 비탈면에 대한 학습데이터는 행정안전부의 실태조사 결과에 대한 전처리 과정을 통해 결측치와 이상치를 제거한 후 전체 데이터의 80%를 훈련용데이터로 분할하고 20%는 시험용데이터로 사용하였으며, 붕괴비탈면에 대해 수행한 정밀조사를 통해 확보된 학습데이터도 동일한 과정을 통해 정보형데이터로 구축한 후 학습을 수행하였다.
4. 비탈면 조사자료의 적합성 검증
4.1 교차검증
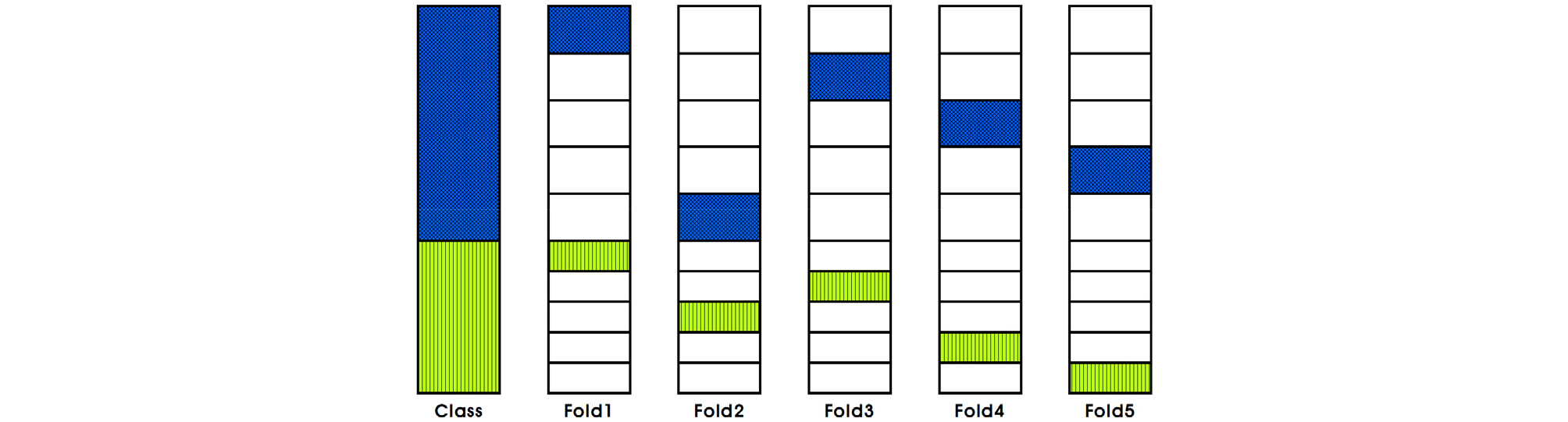
본 연구에서는 머신러닝 모델들을 학습하고 평가하기 위해 주어진 데이터의 일부를 테스트 데이터로 분리하였으며, 테스트 데이터는 모델 학습 시에 사용되지 않고 오로지 모델 평가 시에만 사용하고 나머지 데이터는 교차검증(Cross validation)을 위해 사용하는 방법으로 수행하였다. Stratified K-fold는 불균형 데이터에서 예측 모델의 일반화 성능을 측정하기 위해 모델검증이나 기계학습분야에 자주 사용되며, 각 fold마다 전체 데이터의 클래스 비율(class distribution)을 동일하게 유지하도록 층화(stratification)를 적용한 교차검증 기법으로 Fig. 5와 같은 구조로 학습 데이터를 K개로 나눠 K-1개는 학습 데이터, 나머지 하나는 검증용 데이터가 되고 이걸 각 fold에 대해 반복한다. 이때 각 fold에 특정 클래스가 편중되지 않도록 각 클래스에 따라 비율을 고정해 fold로 나누는 방법을 사용하였다.
4.2 평가지표
혼동행렬(confusion matrix)은 모델이 예측한 결과와 실제 결과를 비교하여 만들어지는 행렬로 Fig. 6과 같이 TP, FP, FN 그리고 TN으로 구성되어 있다. 혼동행렬은 분류 문제에서 결과를 평가하기 위해 자주 사용하는 방법으로 각 항목들을 여러가지 방법으로 조합하여 예측 결과와 실제 결과를 비교할 수 있다.

본 연구에서 평가를 위해 사용된 지표로는 정확도와 민감도, 정밀도 및 특이도, 그리고 F1 score, MCC가 있다. 우선 정확도(Accuracy)는 전체 데이터에서 올바르게 예측된 샘플의 비율로 정의되며, Eq. (1)과 같다.
민감도(Sensitivity, Recall)는 실제 양성(positive) 샘플 중에서 모델이 양성으로 정확히 예측한 비율로 Eq. (2)와 같다.
정밀도(Precision)는 모델이 양성으로 예측한 대상 중에서 실제로 양성인 비율을 지칭하는 것으로 Eq. (3)과 같다.
특이도(Specificity)는 실제 음성(negative) 샘플 중에서 모델이 음성으로 정확히 예측한 비율로 Eq. (4)와 같다.
F1 score는 정밀도(precision)와 민감도(recall)의 조화 평균을 사용해 모델의 성능을 평가하는 방법으로 클래스 간 불균형이 있는 상황에서도 사용할 수 있으며, 0~1까지의 값을 가지며, 1에 가까울수록 더 좋은 성능을 의미한다.
여기서,
MCC는 모든 분류 결과를 균형 있게 평가하는 지표로 confusion matrix의 모든 값을 고려하여 상관관계로서 모델 성능을 나타낸다. -1 ~ 1 사이의 값을 가지며, 1은 완벽한 예측, -1은 완전한 반대 예측을 의미하는 것으로 F1 score보다 더 균형잡힌 평가지표로 Eq. (6)과 같다.
5. 비탈면의 조사결과에 대한 머신러닝(ML) 학습
비탈면붕괴가 발생한 데이터와 비탈면붕괴가 발생하지 않은 데이터 전체의 20%를 독립적인 테스트 데이터로 분리하고, 나머지 80%를 이용해 stratified 5-fold 교차검증을 수행한 후 테스트 데이터에 대한 모델 성능을 평가하였다. 성능 평가는 앞서 설명한 정확도, 민감도, 특이도, F1 score, MCC 순으로 진행하였다.
교차검증 결과, Table 2의 교차검증 결과를 살펴보면, 하이퍼 파라미터 튜닝 후의 XGBoost 모델은 정확도 0.9838, F1 score 0.7293, MCC 0.7266을 기록하며, 대부분의 성능 지표에서 우수한 성능을 나타냈다. 특히, 민감도가 0.7241로 다른 모델 대비 현저히 높아 산사태 발생 예측에 높은 예측 성능을 보였다. Random Forest 모델은 정확도 0.9808, 정밀도 1.000, 특이도 1.000 등의 성능 지표에서 높았으나 민감도 0.3648, F1 score 0.5247, MCC 0.5910으로 산사태 발생 예측에 성능은 상대적으로 매우 낮았다. Extremely randomized tree 모델은 정확도 0.9812, 정밀도 0.9314, 특이도 0.9991에서 높은 성능을 보였지만, Random Forest와 유사하게 산사태 발생 예측 성능이 낮아 민감도 0.4065, F1 score 0.5486, MCC 0.5979를 기록하였다. 반면, Logistic Regression 모델은 정확도 0.9816, 정밀도 0.7954, 특이도 0.9955를 기록하여 산사태 미발생 예측 성능은 다소 낮았지만, 민감도가 0.5373, F1 score 0.6354, MCC 0.6422으로 산사태 발생 예측 성능이 Random Forest, Extremely randomized tree 모델보다 상대적으로 균형있는 성능을 보였다.
Table 2.
Cross-validation performance of machine learning algorithms
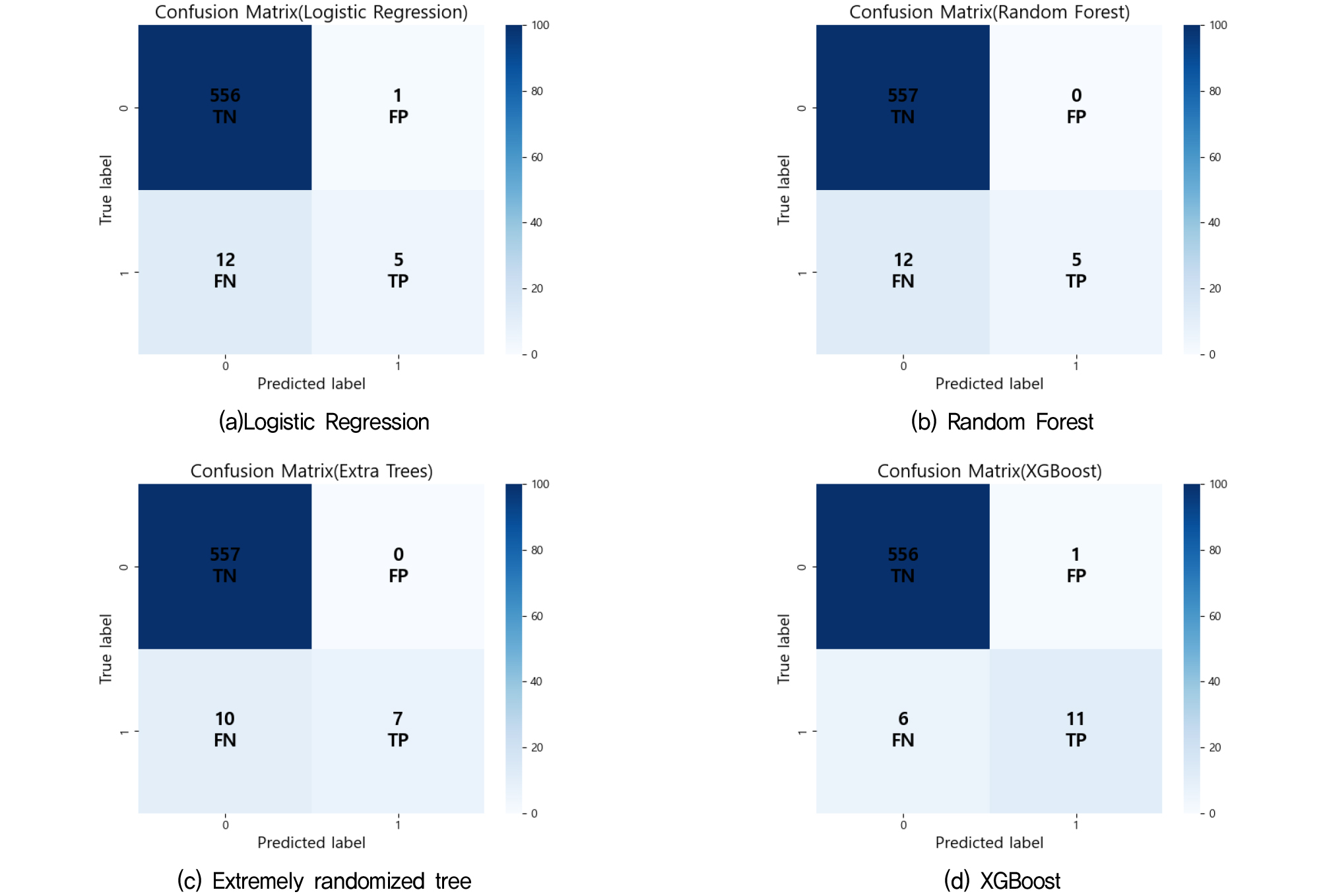
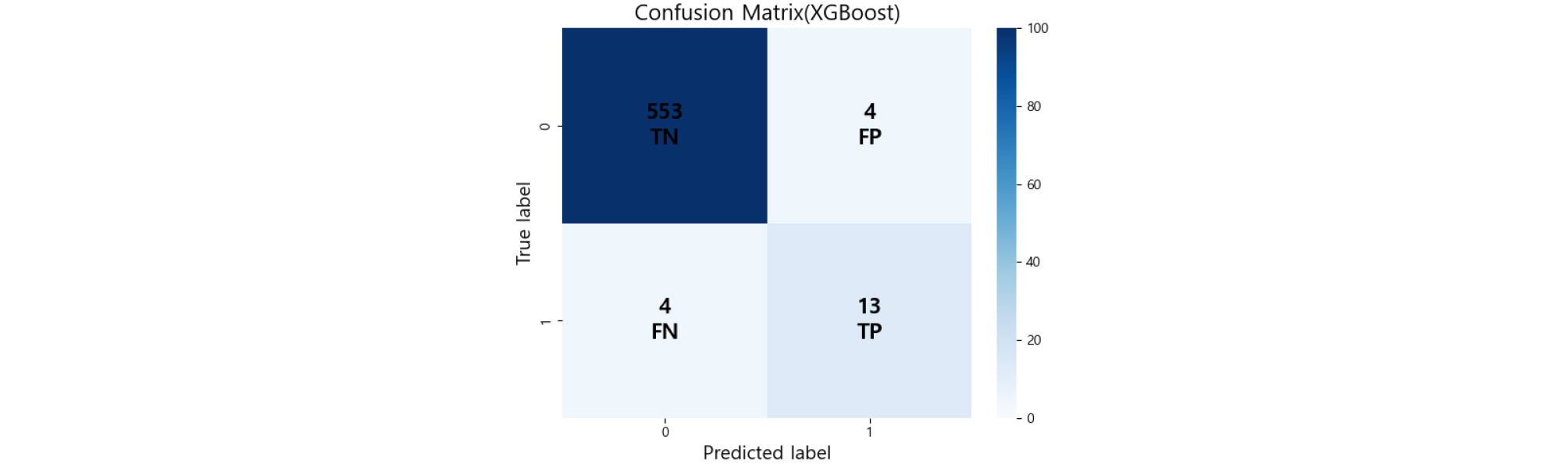
시험 데이터에서 산사태 미발생 557건, 산사태 발생 17건으로 구성되어 있으며, 전체 모델 중 하이퍼 파라미터 튜닝 후의 XGBoost 모델이 가장 우수한 균형 성능을 보였다. Table 3의 결과와 같이 XGBoost는 정확도 0.9860, 민감도 0.7647, 정밀도 0.7647, 특이도, 0.9928, F1 score 0.7647, MCC 0.7575를 기록하여 소수 클래스와 다수 클래스 모두에서 비교적 안정적인 예측 성능을 보였으며, 하이퍼 파라미터 튜닝 후 XGBoost 모델의 혼동행렬 Fig. 8에서 산사태 발생 사례 중 정확히 예측한 참값(TP) 13건과 거짓음성(FN)이 4건으로 상대적으로 높은 민감도를 기록하였다.
Table 3.
Test data performance of machine learning algorithms
또한, 하이퍼 파라미터 튜닝 적용 전 XGBoost 모델의 혼동행렬 Fig. 7(d)와 비교했을 때, FN이 1에서 4건으로 다소 증가하였지만, TP는 11에서 13건으로 증가하여 비탈면 붕괴발생에 대한 탐지 능력이 향상되었다. Extremely randomized tree는 정확도 0.9825, 민감도 0.4117, 정밀도 1.000, 특이도 1.000, F1 score 0.5883, MCC 0.6360으로 두 번째로 우수한 성능을 보였다. 반면, Random Forest(정확도 0.9790, 민감도 0.2941, 정밀도 1.000, 특이도 1.000, F1 score 0.4545, MCC 0.5365)와 Logistic Regression(정확도 0.9816, 민감도 0.5373, 정밀도 0.7954, 특이도 0.9955, F1 score 0.6354, MCC 0.6422)는 다수 클래스인 산사태 미발생 예측 성능은 높았으나 소수 클래스인 산사태 발생 예측 성능이 현저히 낮아 다수 클래스에 과도하게 학습된 것으로 해석된다. 실제로 Logistic Regression과 Random Forest 모델의 혼동행렬 Fig. 7(a)과 Fig. 7(b)에서 각 산사태 발생 중 12건을 TP로, 5건을 FN으로 예측하여, 가장 낮은 민감도를 보였다.
XGBoost(Table 3)는 성능지표가 초모수 튜닝 후 향상되는 결과를 보였으며, 특히 정밀도가 0.7647로 예측한 지역 중 76.5%는 실제로 산사태가 발생했음을 예측했지만, 민감도가 0.7645으로 전체 산사태 발생 지역의 23.5%는 예측하지 못했음을 의미한다.
6. 결 론
본 연구에서는 국내 급경사지를 대상으로 Logistic Regression, Random Forest, Extremely randomized tree, XGBoost 네 가지 머신러닝 알고리즘을 비교하고 비탈면붕괴 발생 예측에 대해 종합적으로 평가하였다.
(1) 기계학습에 사용된 급경사지 데이터는 일반정보와 지반정보 및 재해위험도평가표 상의 붕괴위험성 항목과 사회적영향도 항목 중 지형(경사각, 비탈면최대높이, 횡단형상), 지반지질(지반변형, 절리방향, 풍화도, 붕괴이력), 시설(표면보호 상태) 및 강우(지하수·배수 상태) 등 붕괴 위험인자를 예측 모델 변수로 활용하였다.
(2) 붕괴비탈면에 대한 분석결과 위험인자 중 암반비탈면이 69.9%를 보이고 횡단구조는 요철형(61.1%)이 주를 이루며 높이 5~24m(96.4%)의 범위와 경사각 63° 이상(26.4%)의 범위에서 주로 붕괴가 발생하였다. 풍화도는 중간풍화가 58.2%로 붕괴에 영향을 미치고 특히 비탈면의 붕괴가 절리의 방향과 상당히 밀접한 관계를 가지고 있음을 확인할 수 있다.
(3) 교차검증과 시험 데이터에서 XGBoost는 민감도 0.9838, F1 score 0.7293 및 MCC 0.7266으로 다른 모델에 비해 좋은 성능을 보여 급경사지 분류를 위한 예측모델로 유효할 것으로 판단된다.
(4) 전체 모델 중 하이퍼 파라미터 튜닝 후의 XGBoost 모델이 비탈면 붕괴발생에 대한 탐지능력이 향상되고 우수한 균형 성능을 안정적으로 보여 가장 비탈면붕괴발생 예측에 유리한 것으로 나타났다.
향후 연구에서는 급경사지 붕괴 여부의 분류 정확도를 높이는 것뿐만 아니라, 설명 가능한 인공지능(Explainable AI, XAI) 기법을 활용하여 예측 모형의 결정 과정에 대한 해석력을 확보하고, 붕괴 발생에 영향을 미치는 주요 인자들을 체계적으로 도출하는 연구가 요구된다. 이를 통해 단순한 예측을 넘어, 급경사지 재해의 원인 규명 및 위험 관리 전략 수립에 실질적인 기여를 할 수 있는 과학적 근거를 마련할 수 있을 것으로 기대된다.
